Elastic Search Tips and Tricks for Beginners

As a beginner in elastic search, and the migration in hand, we were tasked to optimize the elastic search, for consumers (via the Rest), and manage the disk space for node-hosts. Here are my findings, some may not have a huge impact but will be helpful one way or either.
- Restricting the mapping
- Selecting few fields as part of the result instead of all fields
- Performing a remap with fixed Mapping
- Improving the Elastic Search by using
Filterinstead ofMust - Indexing Strategy
- Nested Query
- Change Logstash Logging Level
Restricting the mapping
By default, Elastic search will be enabling the dynamic property of the mapping. There are three mapping properties that we can set i.e. strict, true and false. Let's explore each of those in brief.
dynamic: strict
In this type, once the mapping is defined at the start of the index creation, there after if any document that does not match the mapping defined, it will be rejected and not inserted into ES.
dynamic: false
This type is little lenient than the above. In this type, the mapping defined at start, elastic search will not be updating the mapping and will set all the non-mapped fields under the _source but will not be available for querying or keyword searching.
dynamic: true
This is the default type. Whenever the index is created, this is the value set for the dynamic attribute. In this type, elastic search updates the mapping whenever a new field is found. There are multiple data-types in elastic search, and during the decision elastic search will try to find the best data type matching the attribute provided data. However this is available based on a single data source, and such that it could mis-lead elastic-search and it may define a different data-type.
In simple comparison, all the above type has its own advantages and disadvantages. If you have known exact schema, you can define it at the start of the index. If you know the fields you will using for searching or querying you can map those and rest leave as default raw values. And lastly you would like everything searchable and do not know the schema, then let it be dynamic.
In my view, I have seen, dynamic as false do save some KB over a document. In long run it does save me few MBs or even GBs, depending on how much of un-known data is coming to your elastic search.
Performing a remap with fixed Mapping
Let's say you have started with the default setting of the dynamic mapping. And after you have identified the mapping, you reindex the data with fixed mapping to save up space and also make your data look clean and organized.
Firstly you can create a index and define the mapping:
PUT /test
{
"mappings": {
"dynamic": false
"properties": {
"field1": { "type": "text" }
}
}
}
Once done, you can run the re-index api
POST _reindex
{
"source": {
"index": "my-index-000001"
},
"dest": {
"index": "test"
}
}
Once done, you can delete the old-index. I have also observed, once the index mapping is restricted, you can perform your search faster, as the elastic search has lesser but yet more important fields to focus on.
Selecting few fields as part of the result instead of all fields
Using Filter instead of Must
While querying elastic search, it is important on how is your DSL (Domain Specific Language) designed. As per the docs , only the match related query are low weighted and fast depending mapping of the field being queried.
There are multiple ways to query but each of them has their disadvantages due to the way elastic performs the query under the hood.
Indexing Strategy
There is no strategy that fits all solutions!
As such please do take the suggestion in this section (even in the article), as a pinch of salt.
There are often index created based on date month or year based on how many records are expected. Usually, It is recommended to have an index size capped to around 30GB no more than that.
You may also use the customerID as an index, however there are usecases on deciding how to delete the old-data inside the active index. So you also do not want your index to have a forever scope; there should be some dead-line where you will create a new index and archive the older one.
ID-ying the documents
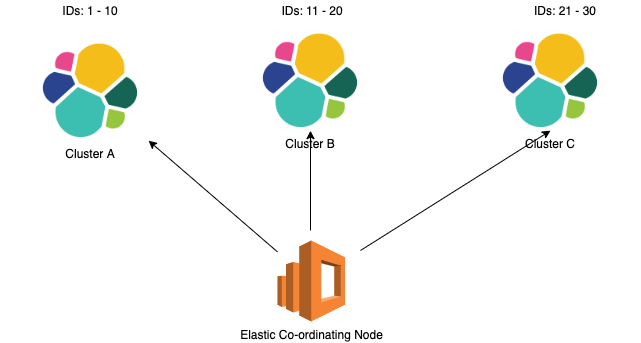
As the id of the document decides on which shard is the document stored, it is useful to create an id that you can use later to search which as such the search query will directly go to the cluster on which the document resides.
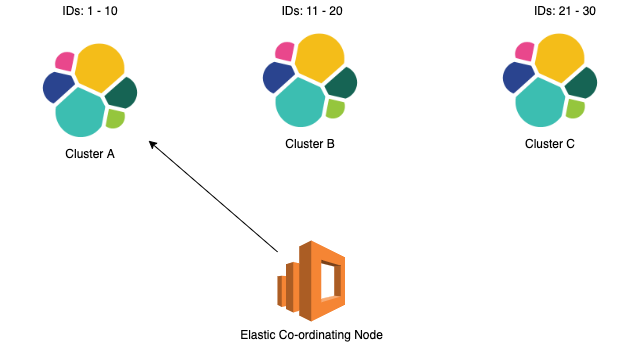
However if the document Id is not known, the co-ordinating node will have to send the query to all the cluster and search for the document, hence making it the expensive operation.
Nested Query
If the field is nested in the index, then simple bool-query may not just do the job.
Lets take an example:
PUT /department
{
"mapping": {
"_doc": {
"properties": {
"employees": {
"type": "nested"
}
}
}
}
}
Here the employees is a nested field. So a simple search like:
GET /department/_search
{
"_source": false,
"query": {
"bool": {
"must": [
{
"match": {
"employees.position": "intern"
}
},
{
"term": {
"employees.gender.keyword": {
"value": "F"
}
}
}
]
}
}
}
The above query will return empty list, in order to the query nested field, there is nested type of query:
GET /department/_search
{
"_source": false,
"query": {
"nested": {
"path": "employees",
"inner_hits": {},
"query": {
"bool": {
"must": [
{
"match": {
"employees.position": "intern"
}
},
{
"term": {
"employees.gender.keyword": {
"value": "F"
}
}
}
]
}
}
}
}
}
Change Logstash Logging Level
In case you would like to change logging level,
curl -XPUT 'localhost:9600/_node/logging?pretty' -H 'Content-Type: application/json' -d'
{
"logger.filewatch.discoverer" : "TRACE",
"logger.filewatch.observingtail" : "TRACE",
"logger.filewatch.sincedbcollection" : "TRACE",
"logger.filewatch.tailmode.handlers.createinitial" : "TRACE",
"logger.filewatch.tailmode.handlers.grow" : "TRACE",
"logger.filewatch.tailmode.processor" : "TRACE"
}
'
Ref: https://discuss.elastic.co/t/logstash-when-started-using-nohup-it-is-logging-too-much-resulting-in-huge-size/276560/7
Thats all for now!
However I will publish more parts to this article as and when I learn new tips that will be helpful in long run.